DOIK) keda를 이용한 mysql server 자동 확장 체험기
지난 네트워크 스터디에 이어 데이터베이스 오퍼레이터 스터디도 참여하게 되었다. 오퍼레이터 자체를 처음 접해서 헷갈리는 것들이 있지만… 그럼에도 중간과제는 찾아온다..! 2주차에서 알게된 mysql operator와 3주차에 알게된 KEDA를 사용하여 mysql 서버 파드를 자동확장 테스트를 하였다.
사용할 mysql operator와 keda를 간략하게 소개하자면,
mysql operator는 쿠버네티스 클러스터 내 mysql innoDB 클러스터를 관리해주는 operator 이다. 🔗
# mysql operator와 mysql-innodbcluster 설치
> helm repo add mysql-operator https://mysql.github.io/mysql-operator/
> helm install mysql-operator mysql-operator/mysql-operator --namespace mysql-operator --create-namespace
> helm install mycluster mysql-operator/mysql-innodbcluster --set credentials.root.password='sakila' --set tls.useSelfSigned=true --namespace mysql-cluster --create-namespace
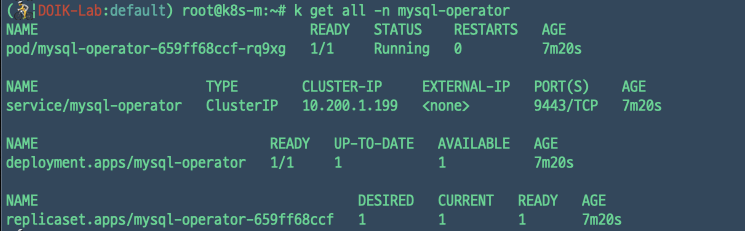
mysql-operator 네임스페이스에는 deployment로 배포된 InnoDB 클러스터를 관리해주는 mysql-operator가 있다.
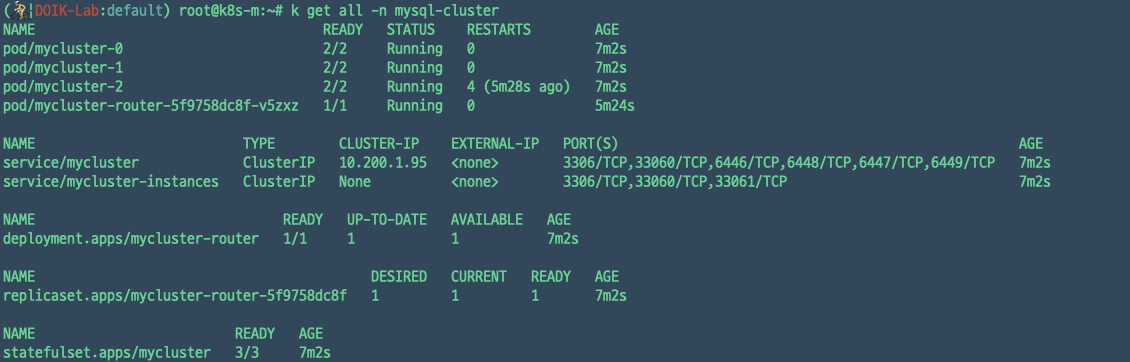
mysql-cluster 네임스페이스에 있는 리소스들이 InnoDB 클러스터 구성한다.
- statefulset/mycluster : mysql server instance
- deployment/mycluster-router : mysql router(proxy 역할)
- service/mycluster : mysql router로 접근됨
- service/mycluster-instances : 특정 서버 접근 시 사용
- configmap/mycluster-initconf : mysql config
KEDA(Kubernetes-based Event Driven Autoscaler)는 특정 이벤트 기반으로 자동 확장해주는 도구이다. 🔗
> helm repo add kedacore https://kedacore.github.io/charts
> helm install keda kedacore/keda --version 2.7.2 --namespace keda --create-namespace
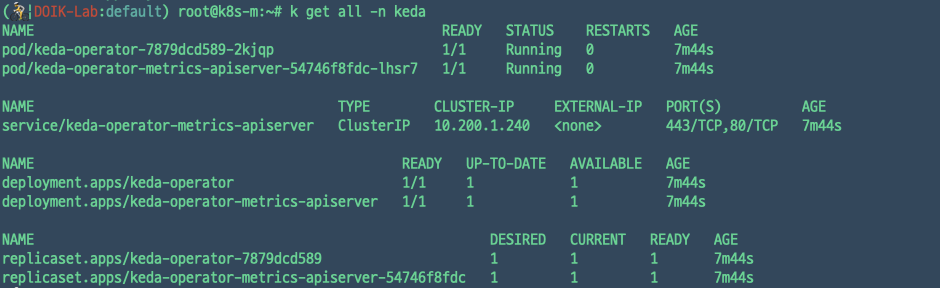
- deployment/keda-operator : agent 역할
- deployment/keda-operator-metrics-apiserver : metric server 역할
테스트
먼저, 테스트를 하기 위해 클라이언트 설치 및 데이터베이스를 생성해줬다.
# mysql client 설치
> apt install mariadb-client -y
# mysql 접근시 사용할 svc ip변수지정
> MYSQLIP=$(kubectl get svc -n mysql-cluster mycluster -o jsonpath={.spec.clusterIP})
# 데이터베이스 및 테이블 생성
> mysql -h $MYSQLIP -uroot -psakila <<EOF
CREATE DATABASE testdb;
CREATE TABLE testdb.testtable (testcolumn1 INT PRIMARY KEY,testcolumn2 TEXT NOT NULL);
INSERT INTO testdb.testtable VALUES (1, 'none');
EOF
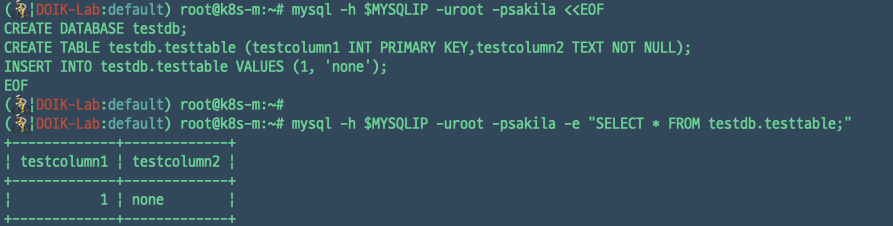
데이터베이스가 생성되고 넣은 값이 잘 들어갔는지 확인
keda.yaml
keda를 사용하기 위해 확장할 개체를 정의해준다. 🔗
apiVersion: v1
kind: Secret
metadata:
name: mysql-secrets
type: Opaque
# base64로 인코딩하여야함
# $echo -n 'value' | base64
data:
mysql_host: bXljbHVzdGVyLWluc3RhbmNlcy5teXNxbC1jbHVzdGVyLnN2Yy5jbHVzdGVyLmxvY2Fs
# mycluster-instances svc domain
mysql_port: MzMwNg==
mysql_db: dGVzdGRi
mysql_user: cm9vdA==
mysql_password: c2FraWxh
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-mysql-secret
spec:
secretTargetRef:
# 자격증명을 위해 위에서 만들었던 secret 내용들을 넣어줌
# https://keda.sh/docs/1.4/concepts/authentication/#re-use-credentials-and-delegate-auth-with-triggerauthentication
# parameter 참고
# https://keda.sh/docs/2.7/scalers/mysql/
- parameter: host
name: mysql-secrets
key: mysql_host
- parameter: port
name: mysql-secrets
key: mysql_port
- parameter: dbName
name: mysql-secrets
key: mysql_db
- parameter: username
name: mysql-secrets
key: mysql_user
- parameter: password
name: mysql-secrets
key: mysql_password
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: mysql-scaledobject
spec:
# 다른 옵션 참고
# https://keda.sh/docs/2.7/concepts/scaling-deployments/
pollingInterval: 1 # default 30s
cooldownPeriod: 10 # default 300s
minReplicaCount: 1 # default 0
maxReplicaCount: 10 # default 100
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet # default Deployment
name: mycluster
envSourceContainerName: mysql
# 미지정시 첫번째 컨테이너 속성을 가져옴
# .spec.template.spec.containers[0]
advanced:
restoreToOriginalReplicaCount: true # default false
# ScaledObject 삭제 시 늘어난 복제 수를 유지하지 않고 기존에 지정한 복제 수로 돌아옴
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
- type: mysql
metadata:
# 임계값지정
queryValue: "3" # 단일 숫자여야함
query: "SELECT CEIL(COUNT(*) / 6) FROM testdb.testtable WHERE testcolumn2='none'"
authenticationRef:
name: keda-trigger-auth-mysql-secret

배포 후 describe으로 리소스 이벤트를 확인해보면 성공적으로 배포된 것을 확인 할 수 있다.
📈 자동 확장 테스트
# 데이터 추가
> for ((i=1; i<=100; i++)); do mysql -h $MYSQLIP -uroot -psakila -e "SELECT @@HOSTNAME;INSERT INTO testdb.testtable VALUES ($i, 'none');";echo; done
# sql server pod 증가 모니터링
> watch -n 1 -d "kubectl get pod -o wide -n mysql-cluster"
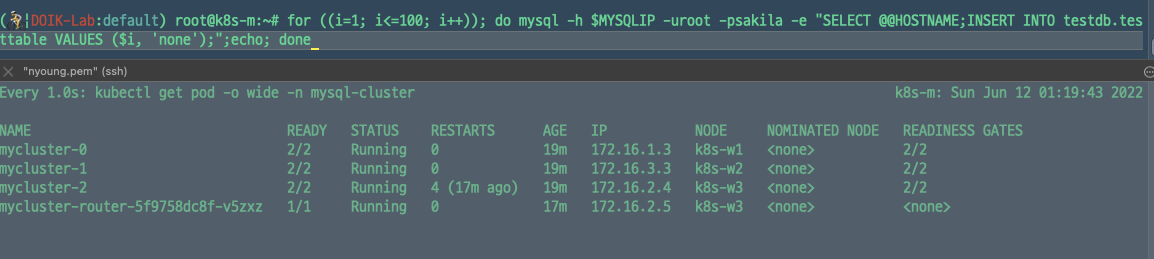
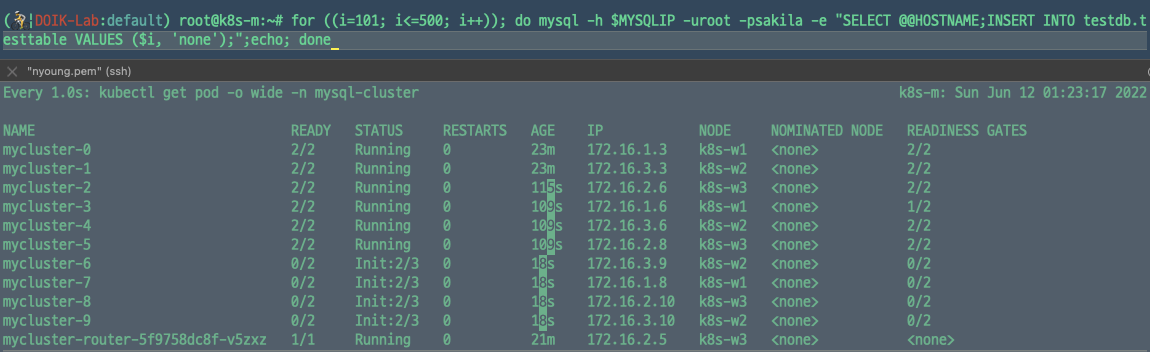
100개의 데이터를 넣으면 mycluster-5까지, 500까지 늘렸을 때에는 9까지 파드가 생성되는 것을 확인할 수 있었다.
📉 자동 축소 테스트
# 데이터 삭제
> for ((i=101; i<=500; i++)); do mysql -h $MYSQLIP -uroot -psakila -e "SELECT @@HOSTNAME;INSERT INTO testdb.testtable VALUES ($i, 'none');";echo; done
# sql server pod 감소 모니터링
> watch -n 1 -d "kubectl get pod -o wide -n mysql-cluster"
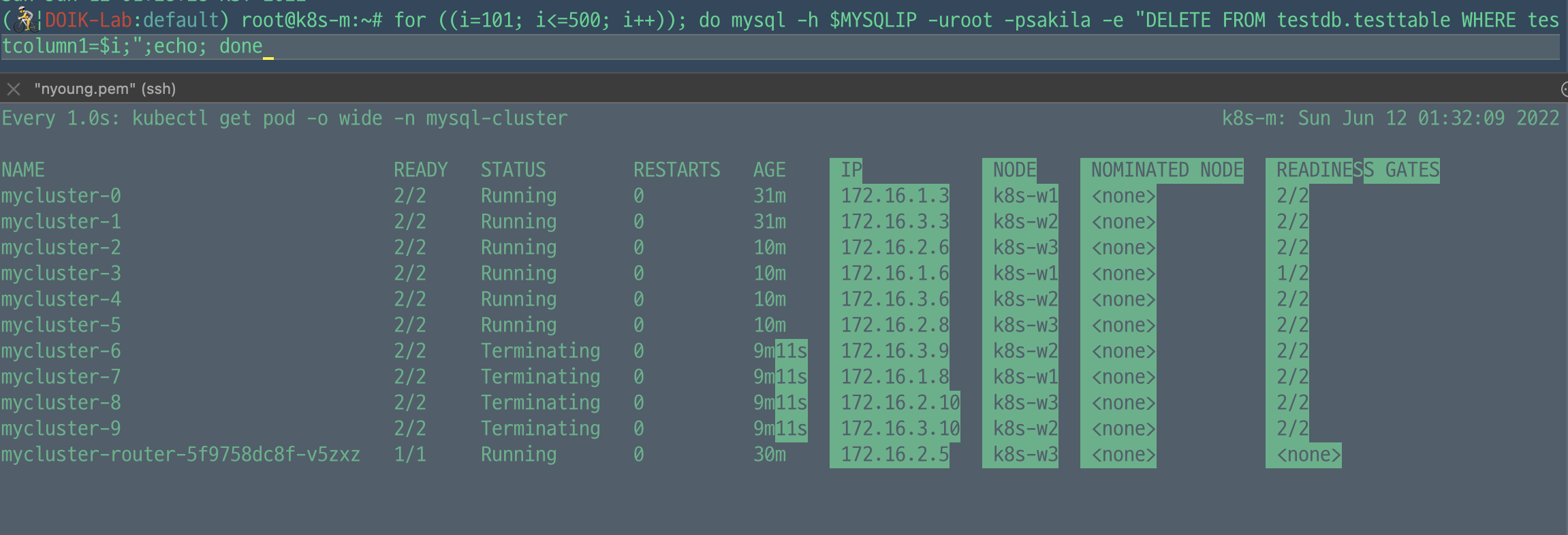
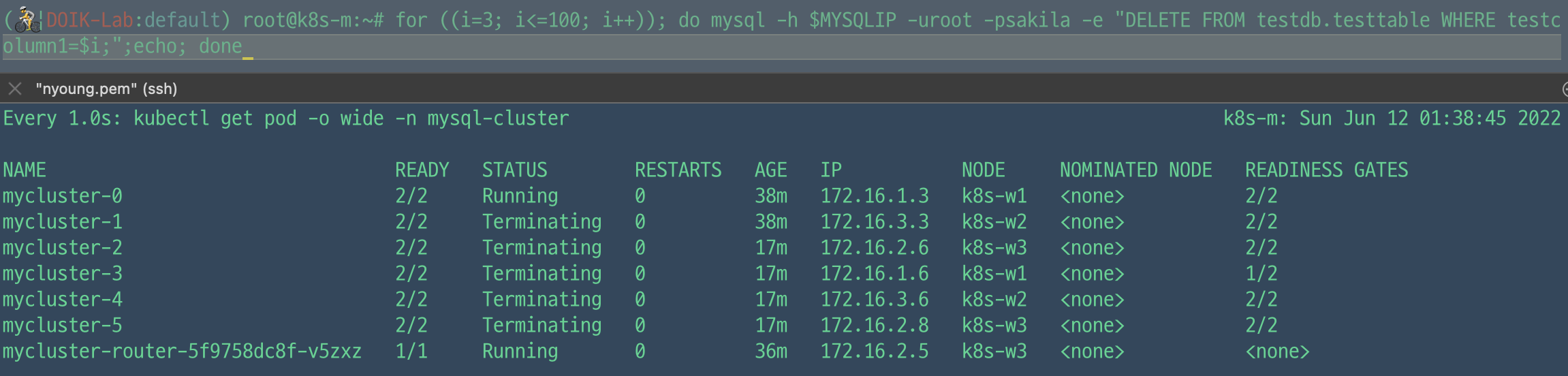
400개를 먼저 지워봤을 때 증가 테스트 시 늘어난만큼 삭제되는 것을 확인할 수 있었다. 나머지 데이터들도 2개 빼고 모두 삭제 시 하나의 파드를 제외하고 모든 파드가 삭제되었다.
🚧 해당 테스트를 진행하며 마주했던 오류들
오류1 Warning KEDAScalerFailed 6s (x12 over 16s) keda-operator error resolving secrets for ScaleTarget: couldn’t find container with name .spec.template.spec.containers[0] on Target object
▶️ ScaledObject를 정의하는 파일에서 spec.scaleTargetRef.envSourceContainerName에 컨테이너 명을 적어야한다. 이런식으로 *spec.template.spec.containers[0] 적어서 발생한 오류였다.
오류2 Warning KEDAScalerFailed 0s (x10 over 3s) keda-operator error establishing MySQL connection: dial 10.200.1.135: unknown network 10.200.1.135
▶️ 처음에 Secret 파일에서 data.mysql_conn_str으로 mycluster svc ip를 넣었었는데 오류가 발생하여 router가 아닌 서버에 직접 연결되는 mycluster-instances svc를 host에 넣었다.
참고