pkos) prometheus 체험기
이번 주 스터디에서는 모니터링과 로깅쪽 내용을 다루었다. 테스트 환경은 aws ec2에 kops를 사용하여 만든 클러스터 위에서 테스트하였다.
 이미지 링크🔗
이미지 링크🔗
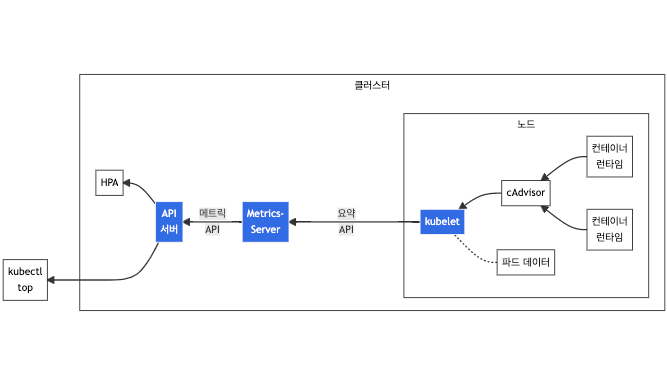
쿠버네티스에서 리소스의 사용량을 확인하기 위한 kubectl top 명령어 같은 경우는, kubelet에 내장되어있는 cAdvisor를 통해 컨테이너 메트릭이 수집되는 것이다. 아래 명령어로 확인해 보면 cpu와 memory의 사용량 확인이 가능한 것을 볼 수 있다.
❯ k top po -A
NAMESPACE NAME CPU(cores) MEMORY(bytes)
kube-system aws-cloud-controller-manager-vg7xh 2m 21Mi
kube-system aws-load-balancer-controller-654b56fbbf-jdqkz 2m 22Mi
kube-system aws-node-46gzf 2m 37Mi
kube-system aws-node-ktpxj 3m 37Mi
kube-system aws-node-lndb7 2m 38Mi
컨테이너 내부에서의 메트릭 수집과 모니터링이 필요한 경우에는 cAdvisor로도 충분하지만, 노드의 리소스 사용률 등의 메트릭이 필요하다면, node exporter가 필요하다.
prometheus
 이미지 링크🔗
이미지 링크🔗
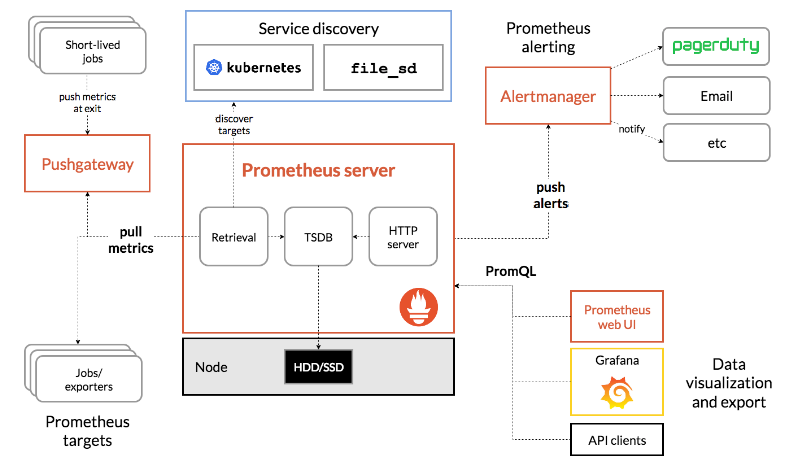
prometheus의 아키텍처를 보면 node exporter로부터 pull방식으로 메트릭을 수집해서 tsdb에 저장하게 된다. 이렇게 수집한 것들을 토대로 prometheus에서 제공하는 web ui로 확인하거나 grafana를 통해 시각화하여 볼 수도 있다.
설치
❯ k create ns monitoring
namespace/monitoring created
❯ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
❯ vi ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.nyoung.xyz
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.nyoung.xyz
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.nyoung.xyz
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
❯ helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 --set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' -f ~/prometheus/values.yaml -n monitoring
# 테스트이기 때문에 interval을 짧게 조정
# scrape_interval: 메트릭 가져오는 주기
# evaluation_interval: alert을 보낼지말지 판단하는 주기
❯ kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.66.233.48 <none> 9100/TCP 87s
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus-node-exporter 172.30.44.190:9100,172.30.45.83:9100,172.30.84.143:9100 87s
# nodeexporter가 9100이 열고 있는 것을 확인
rule 추가
상단의 alerts으로 가보면, 기본적으로 생성되어있는 rule들을 확인 할 수 있다. prometheus 배포시 만들어지는 rule에서 임계치를 조정하여 알림을 설정하거나, 애플리케이션들을 위한 rule을 새롭게 추가할 수도 있다. prometheus에서 여러 서비스에 대해 rule yaml을 제공하고 있다. 🔗
❯ k get prometheusrules.monitoring.coreos.com kube-prometheus-stack-node-exporter -oyaml -n monitoring > prometheusrules.yaml
# 생성된 파일 하단에 prometheus에서 제공하는 nginx 내용을 복사 후 붙여넣음
...
# 테스트시 빠르게 하기 위해 5m > 1m으로 조정
- name: nginx-exporter
rules:
- alert: NginxHighHttp4xxErrorRate
annotations:
description: |-
Too many HTTP requests with status 4xx (> 5%)
VALUE =
LABELS =
summary: Nginx high HTTP 4xx error rate (instance )
expr: sum(rate(nginx_http_requests_total{status=~"^4.."}[1m])) / sum(rate(nginx_http_requests_total[1m]))
* 100 > 1
for: 1m
labels:
severity: critical
- alert: NginxHighHttp5xxErrorRate
annotations:
description: |-
Too many HTTP requests with status 5xx (> 5%)
VALUE =
LABELS =
summary: Nginx high HTTP 5xx error rate (instance )
expr: sum(rate(nginx_http_requests_total{status=~"^5.."}[1m])) / sum(rate(nginx_http_requests_total[1m]))
* 100 > 1
for: 1m
labels:
severity: critical
- alert: NginxLatencyHigh
annotations:
description: |-
Nginx p99 latency is higher than 3 seconds
VALUE =
LABELS =
summary: Nginx latency high (instance )
expr: histogram_quantile(0.99, sum(rate(nginx_http_request_duration_seconds_bucket[2m]))
by (host, node)) > 3
for: 2m
labels:
severity: warning
...
❯ k apply -f prometheusrules.yaml
# status > rules에 가면 추가된 것을 확인할 수 있음
test를 위한 nginx 설치
❯ helm repo add bitnami https://charts.bitnami.com/bitnami
❯ helm fetch bitnami/nginx --untar
...
33 clusterDomain: nyoung.xyz
517 type: ClusterIP
581 ingress:
584 enabled: true
596 hostname: nginx.nyoung.xyz
611 annotations:
612 alb.ingress.kubernetes.io/scheme: internet-facing
613 alb.ingress.kubernetes.io/target-type: ip
614 alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
615 alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
622 ingressClassName: alb
685 hostname: nyoung.xyz
763 metrics:
766 enabled: true
769 port: 9113
807 service
810 port: 9113
813 annotations:
814 prometheus.io/scrape: "true"
815 prometheus.io/path: "/metrics"
816 prometheus.io/port: ""
839 serviceMonitor:
842 enabled: true
845 namespace: monitoring
...
❯ helm upgrade nginx bitnami/nginx --version 13.2.23 -f nginx/values.yaml
# container 가 두개 띄워진 것을 확인
(nyoung:N/A) [root@kops-ec2 ~]# kubectl get pod -l app.kubernetes.io/instance=nginx
NAME READY STATUS RESTARTS AGE
nginx-697fd655bf-gj8f7 2/2 Running 0 100s
# describe으로 확인해보면 nginx와 nginx-exporter가 함께 설치된 것을 확인
Normal Pulled 96s kubelet Successfully pulled image "docker.io/bitnami/nginx:1.23.3-debian-11-r17" in 4.874078894s
Normal Created 96s kubelet Created container nginx
Normal Started 95s kubelet Started container nginx
Normal Pulling 95s kubelet Pulling image "docker.io/bitnami/nginx-exporter:0.11.0-debian-11-r44"
Normal Pulled 92s kubelet Successfully pulled image "docker.io/bitnami/nginx-exporter:0.11.0-debian-11-r44" in 3.593249748s
Normal Created 92s kubelet Created container metrics
Normal Started 92s kubelet Started container metrics
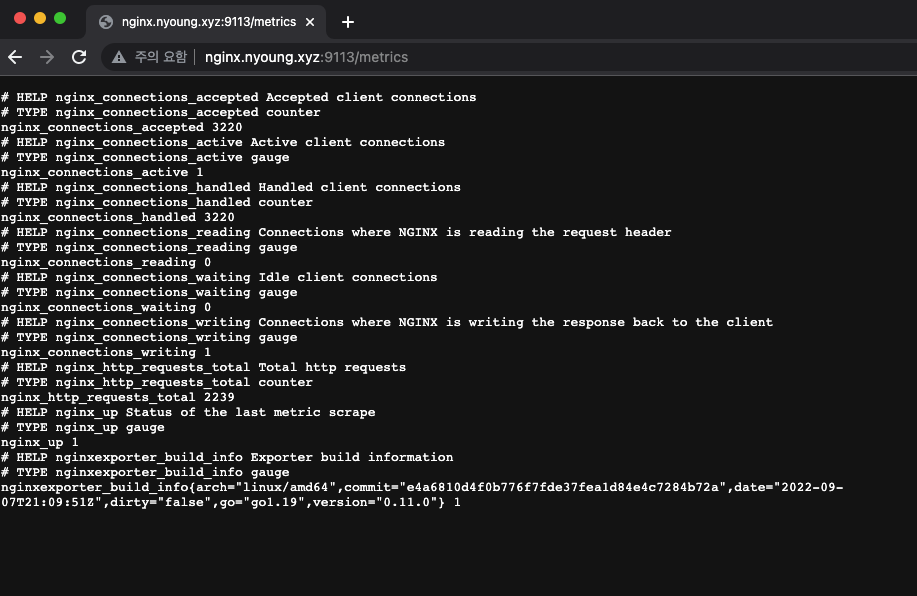
nginx_ip:9113/metrics에 가면 수집중인 것을 확인 할 수 있다.
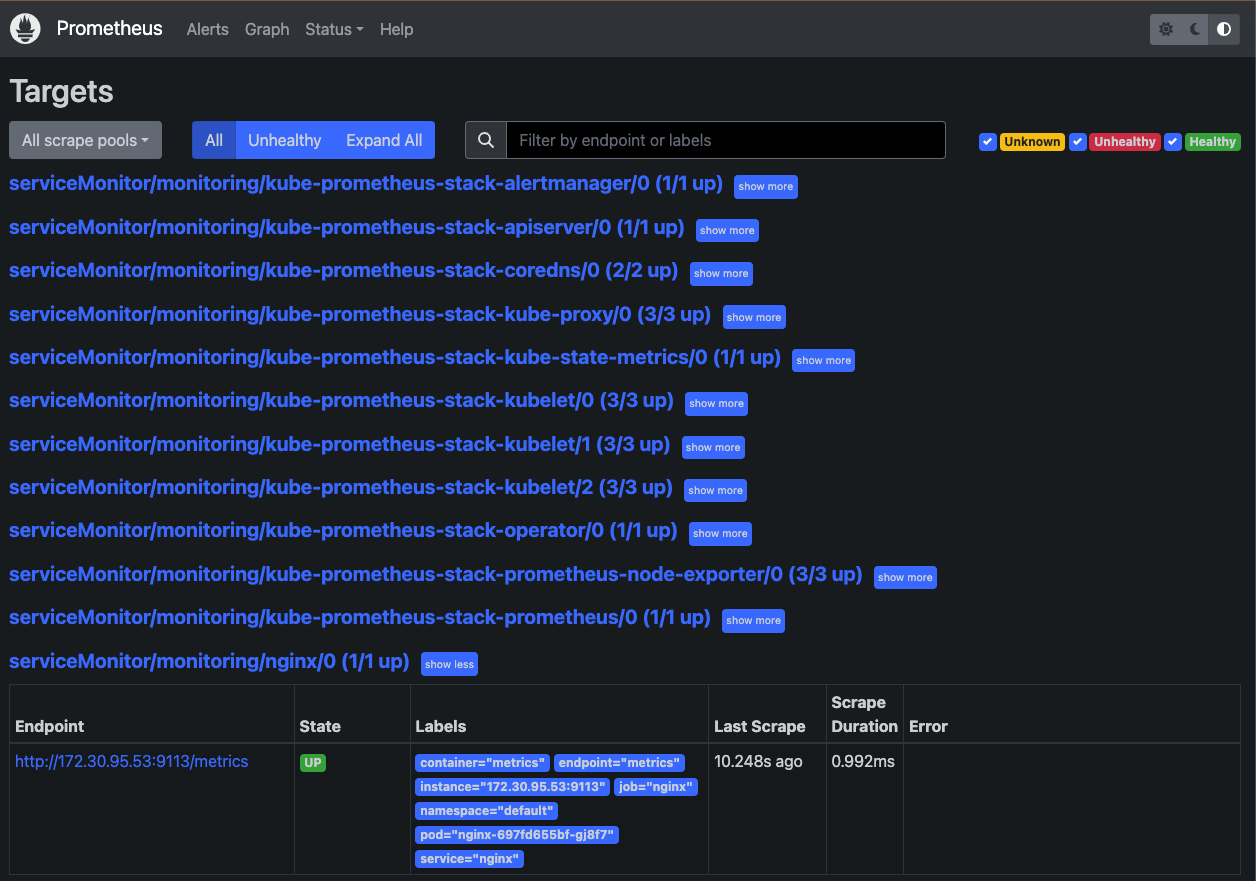
prometheus에는 service discovery라는 기능이 있어서 클러스터내에 리소스 생성시 자동으로 target으로 등록된다. 가장 밑에 serviceMonitor/monitoring/nginx/0으로 endpoint까지 잘 붙어있는 것을 확인 할 수 있다.
grafana alert
prometheus 설치하며 같이 설치했던 grafana에 접속해보면 스택으로 한번에 올렸기때문에 데이터 소스가 기본적으로 프로메테우스가 추가되어있는 것을 확인할 수 있다.
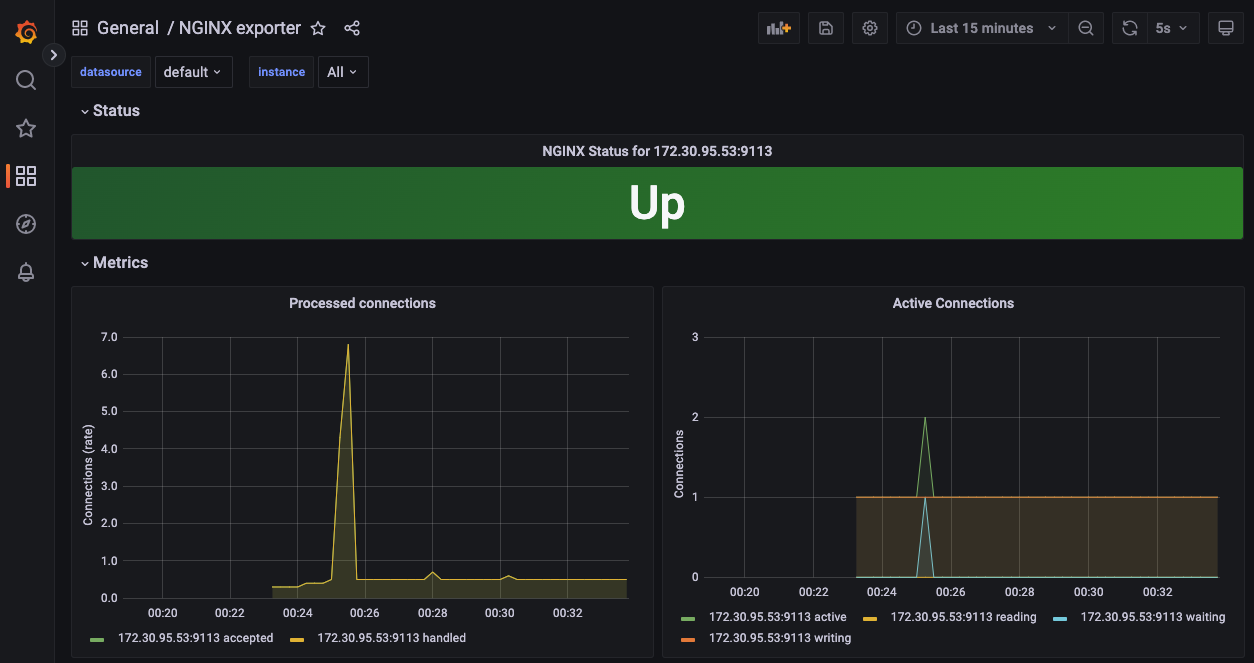
dashboard > import > 12708을 입력하여 nginx monitoring dashboard를 추가해줬다. 🔗
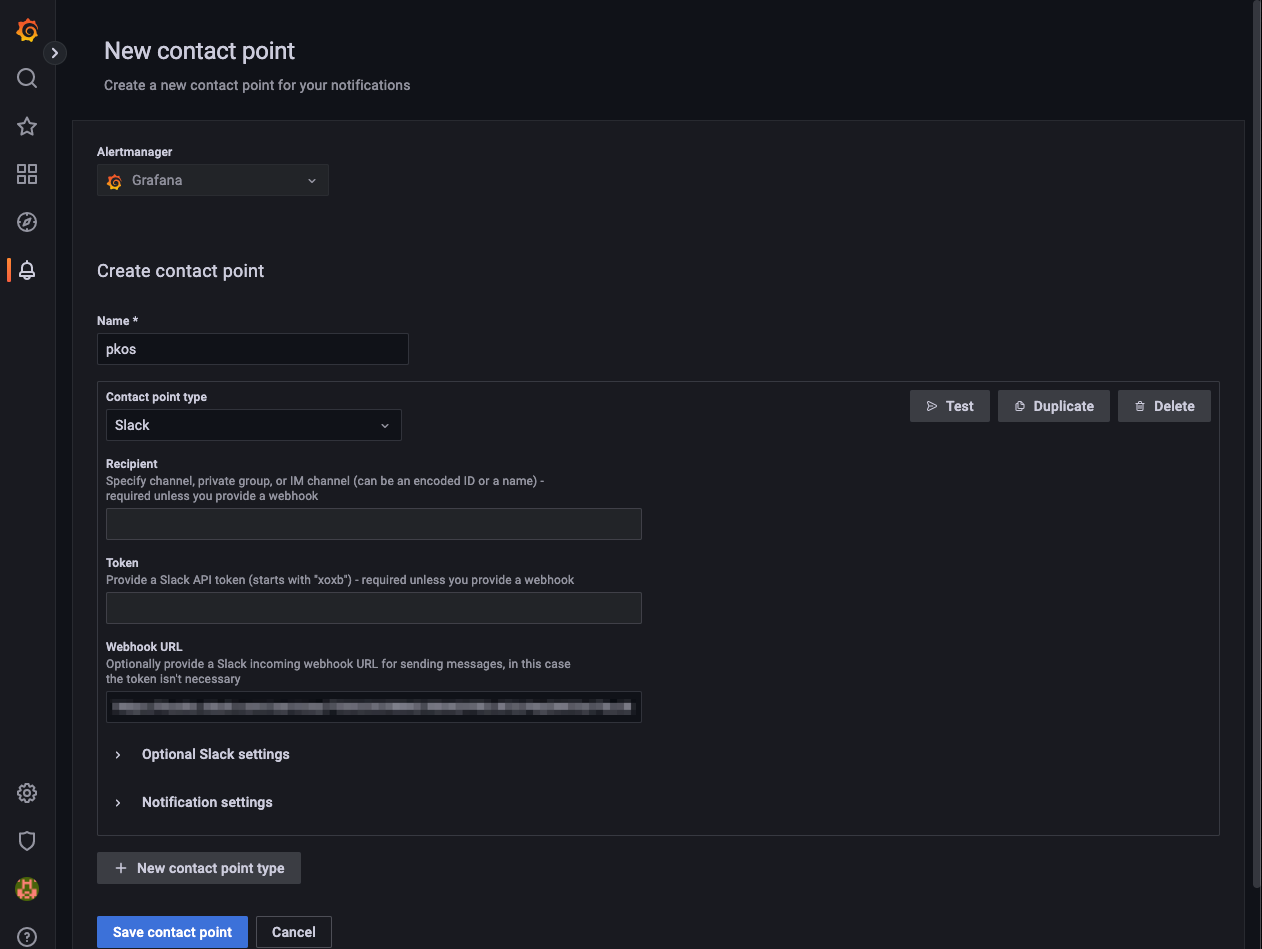
alerting > contact points > new contact point를 통해 알림을 받을 곳을 등록해준다. 등록 후 테스트를 하게되면 아래와 같이 잘 등록된 것을 확인 할 수 있다.
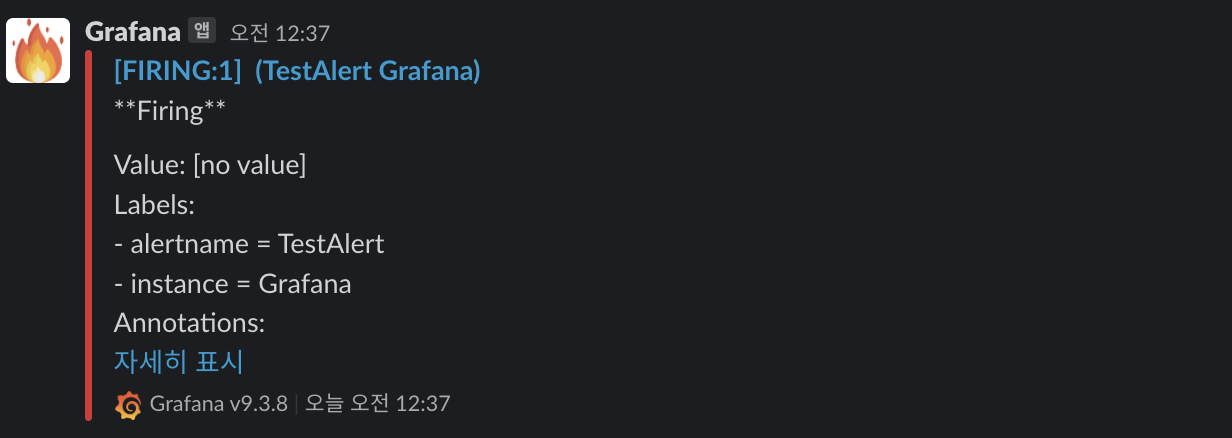
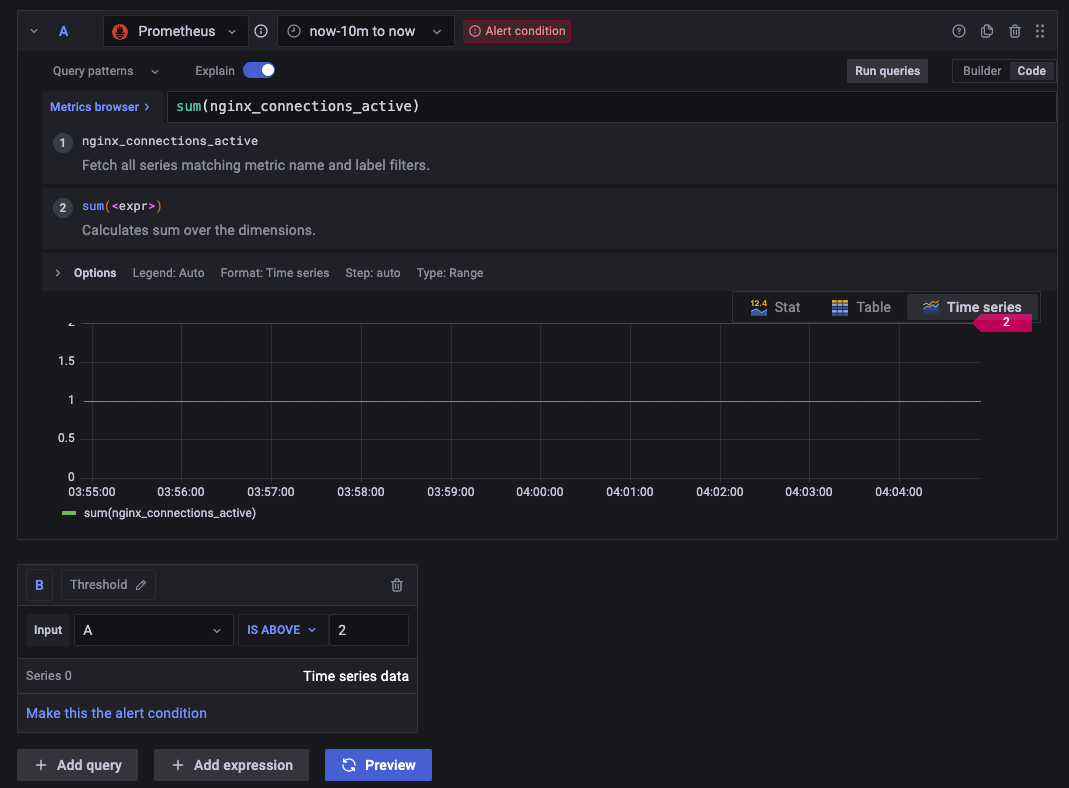
alerting > notification policies > new policy에서 새로운 alert 정책을 생성해준다. 테스트로는 nginx_connection_active의 합계가 임계치 2보다 높을 경우 알람이 전달되도록 생성했다.
임계치가 넘도록 지속적으로 호출을 해주었다.
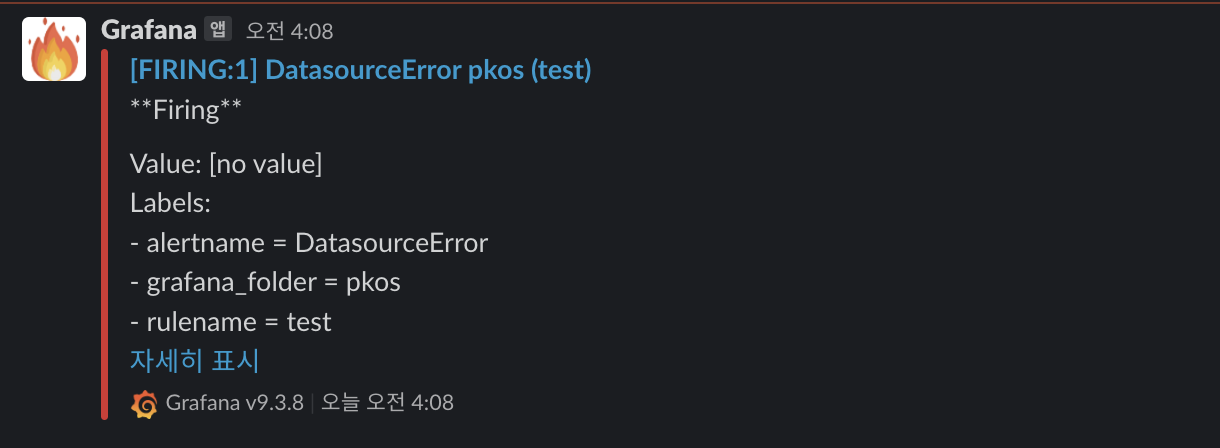
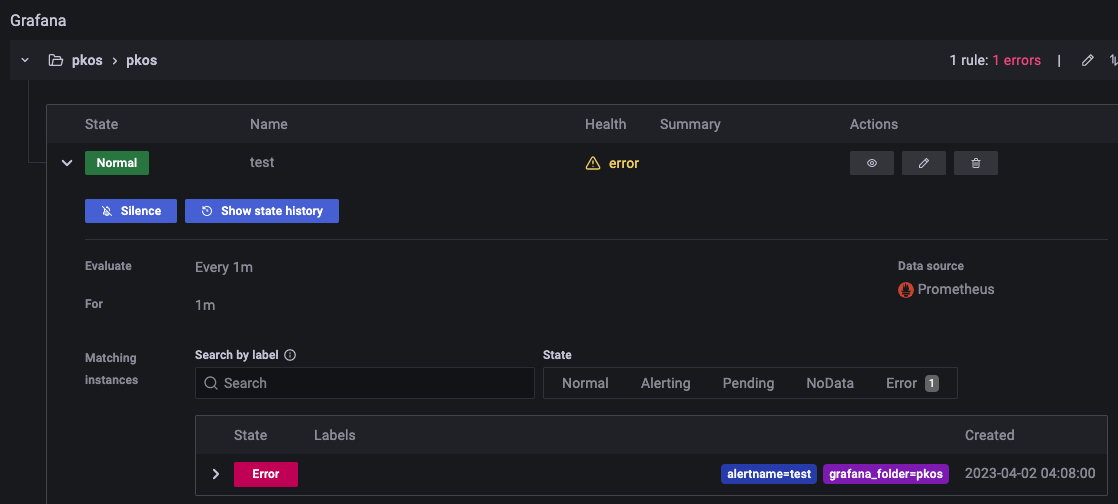
그 결과, grafana에서의 arlert 정책의 health 상태도 error이며 이에따라 슬랙으로도 메세지가 전달되었다.
원래는 위에서 prometheus에 rule을 넣어준 상태코드값으로 alert정책을 만들려 했는데.. 왜인지.. status code값을 가져오지를 못한다 😇 prometheus에서 scrape config를 추가도 해줘보고 nginx exporter 부분도 변경해보고 혹시나 권한문제일까 clusterrole에 과분하게 권한도 줘봤지만.. 해결하지 못했다. 오ㅐ일까 .. .
참고