aews) eks karpenter 체험기
이번 주차는 eks autoscaling이였다. 업무에서 보통 gcp를 사용하다보니, aws를 볼 일이 거의 없는데 모두가 입을 모아 karpenter를 찬양해서 궁금하여 숙제할겸 사용해봤다.
karpenter
karpenter 전에도 cluster autoscaler를 써서 노드가 부족할 시 생성될 수 있도록 설정이 가능하긴 했다. 이때에는 instance gruop의 asg(auto scaling group)을 이용하게되는데, eks와 asg 간에 동기화가 되지않아 불편함이 있다. 예를 들어, 요구되는 리소스가 축소될 때 특정 노드가 축소되도록 설정하기가 어렵거나 eks의 노드에서는 제거되었더라도 인스턴스는 남아있게 되는 등 관리가 어렵다. karpenter를 사용하면 이러한 문제점들을 모두 해결할 수가 있다. 스케줄링안된 파드가 위와 같이 cluster autoscaler를 통해 asg에서 인스턴스가 확장되는 방식이 아니라, 바로 karpenter를 통해 ec2를 추가하게된다. karpenter는 스케줄링 안된 파드를 발견하면 가장 저렴한 인스턴스로 생성하여 노드 추가하게된다. 이 때 pv 붙은 노드를 위해 따로 단일 서브넷 위에 노드그룹을 만들지 않아도 자동으로 pv가 존재하는 서브넷에 노드를 만든다. 또, 요구되는 리소스가 줄어들 때에도 알아서 노드를 정리해준다. 예를 들어, 남아있는 파드가 여러 노드에 올라가 있는데 노드들이 여유있다면 파드를 다시 띄워 노드 하나에 정리해서 합쳐준다. 너무나도 똑똑한 카펜터..
install karpenter
이 링크를 따라하면..! 🔗 karpenter가 사용할 irsa를 설정하며, eks cluster를 생성해준다. (위 링크에서의 1~3작업)
test
4번을 따라 default provisioner를 배포했다. 설정 값 중에 ‘ttlSecondsAfterEmpty: 30’가 있는데, 이 값이 있어야 node scale down이 가능하다. 설정시간만큼 데몬셋을 제외한 파드가 없을 경우, 노드를 삭제하는 옵션이다. 🔗
아래에 테스트로 있는 deploy yaml을 그대로 사용했다. deploy를 보면 최소 cpu 1m을 필요로 하게끔 작성되어있어서, 배포하게되면 파드들이 들어갈 수 있을 노드가 배포된다.
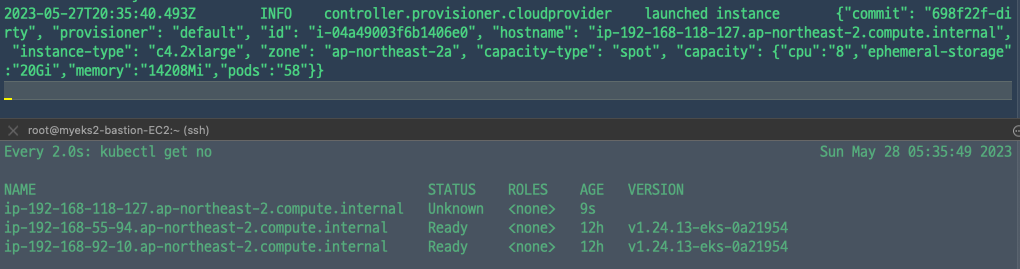 $ kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
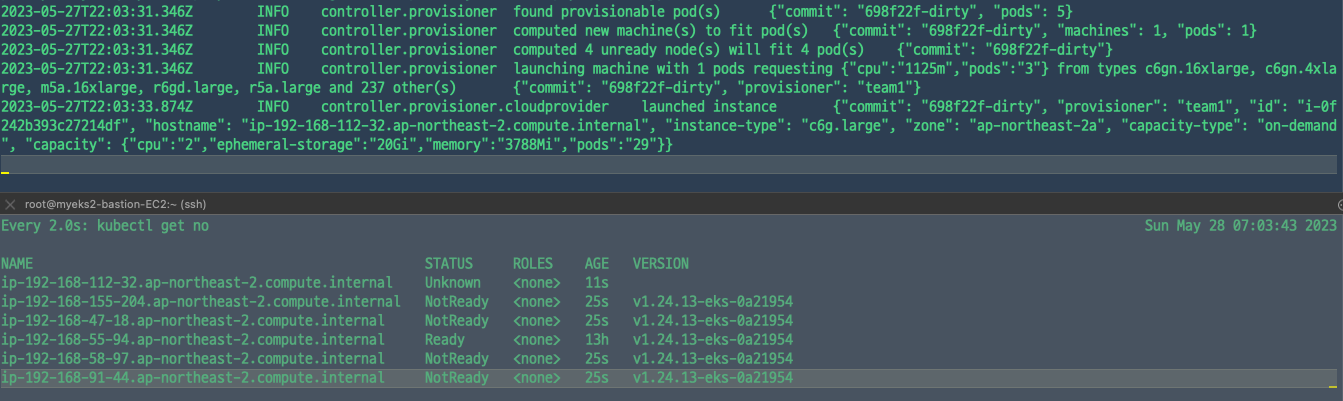
karpenter의 로그를 찍어보면 인스턴스가 배포되는 것을 확인할 수 있다.
$ kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
karpenter의 로그를 찍어보면 인스턴스가 배포되는 것을 확인할 수 있다.
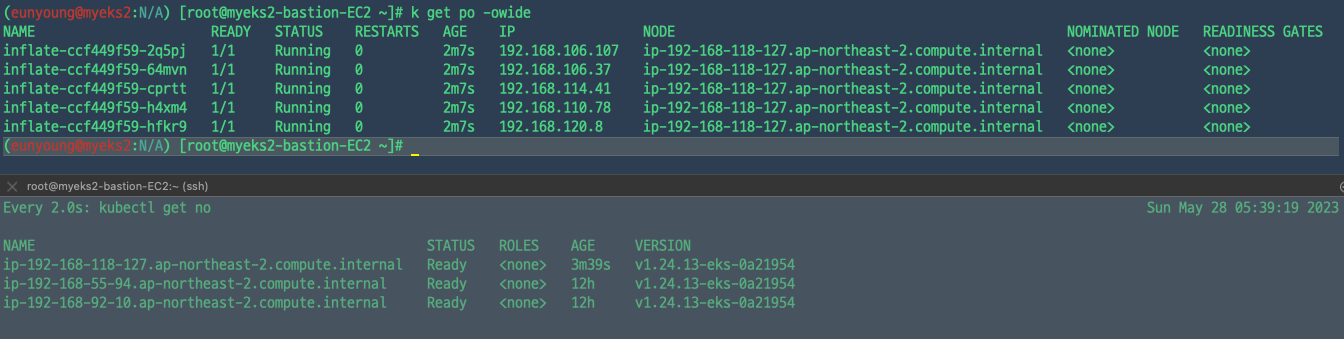
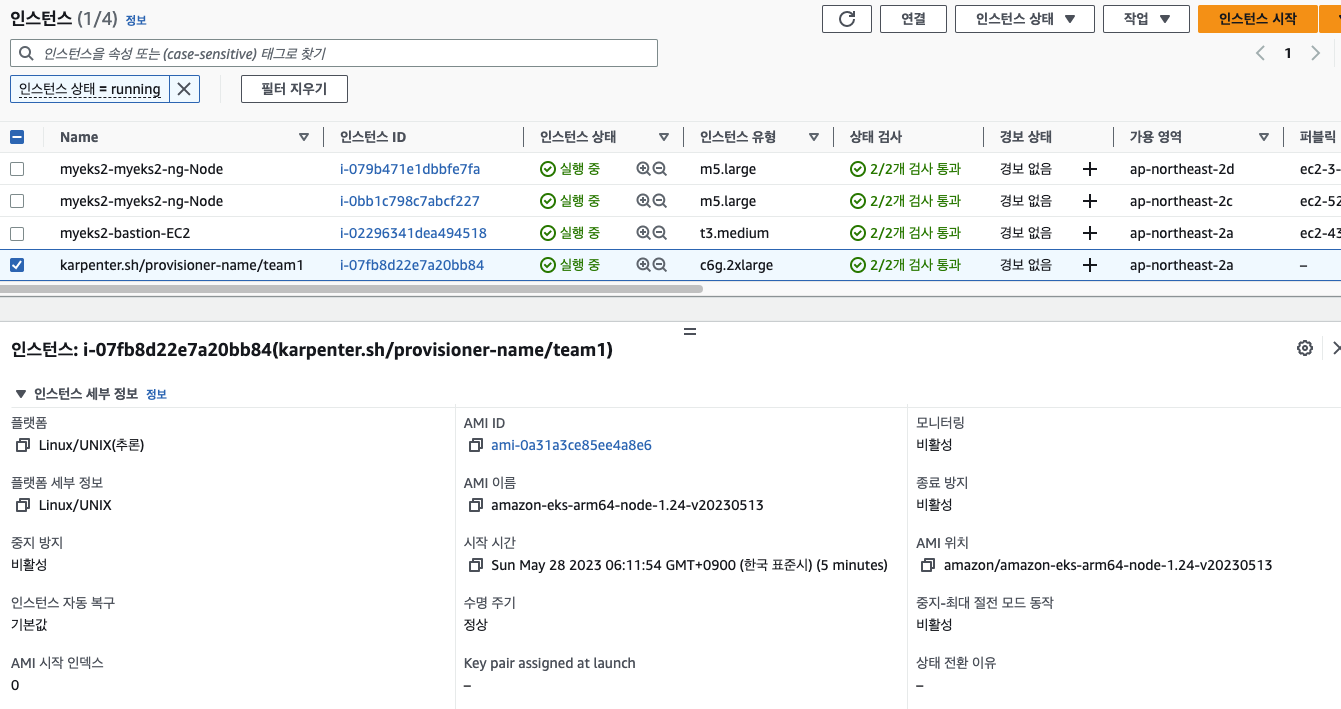
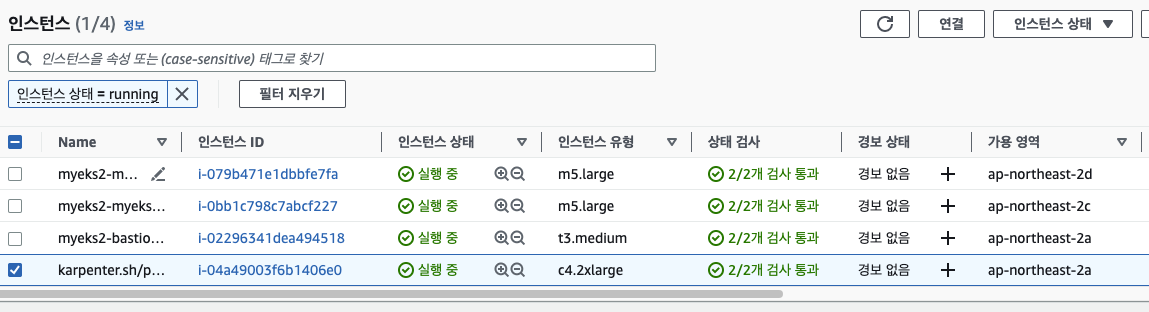 5개의 파드가 들어간 노드가 생성되었다. 캡처를 못떴는데, 인스턴스 상세보기를 통해 spot instance로 생성된 것을 볼 수 있다.
5개의 파드가 들어간 노드가 생성되었다. 캡처를 못떴는데, 인스턴스 상세보기를 통해 spot instance로 생성된 것을 볼 수 있다.
multi provisioner 🔗
# provisioner 생성
cat <<EOF | kubectl apply -f -
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: team1
spec:
labels:
team: team1
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64","arm64"]
limits:
resources:
cpu: 1000
providerRef:
name: default
ttlSecondsAfterEmpty: 30
---
apiVersion: karpenter.k8s.aws/v1alpha1
kind: AWSNodeTemplate
metadata:
name: team1
spec:
subnetSelector:
karpenter.sh/discovery: ${CLUSTER_NAME}
securityGroupSelector:
karpenter.sh/discovery: ${CLUSTER_NAME}
tags:
KarpenerProvisionerName: "team1"
EOF
# 테스트할 deployment
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 0
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "team"
operator: "In"
values: ["team1"]
EOF
kubectl scale deployment inflate --replicas 5
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller
amd64,arm64 cpu를 사용하는 인스턴스이면서 spot이 아닌 ondemand instance로 provisioner를 생성하였다. multi provisioner일때 선택할 수 있는 방안은 노드를 선택한다고 생각하면 된다. label을 지정하거나, taint와 tolerance를 사용하여 배포 할 수 있다. 🔗
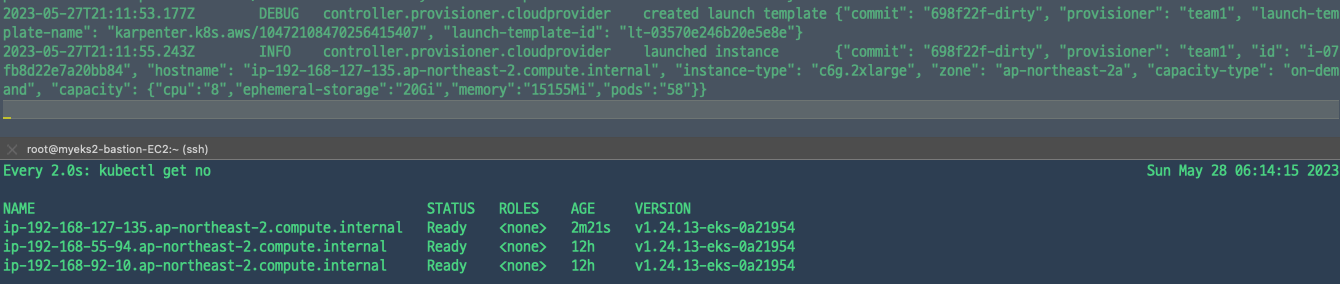
독스 예시에 있는 spec.amiFamily: Bottlerocket 옵션을 넣은 provisioner를 생성 후 테스트해봤었는데, 이미지를 제대로 가져오지 못해 찾아보니 현재 구성을 지원하지 않는 다고한다. 혹시나.. 누군가 테스트를 하신다면.. 🔗
keda와 함께
karpenter가 이렇게 편리하고 좋은데..! 만약 대규모로 확장이 필요한 경우에는 karpenter만으로는 확장하는 속도를 못따라 갈 수 있다는 것을 봤다. 🔗 ec2가 뜨고 그 위에 데몬셋이 모두 설치되는데에 시간이 필요하기 때문에 오버프로비저닝이 필요한 경우 keda를 활용할 수 있다는 것을 봤다. keda는 특정 이벤트가 발생하였을 때 자동확장해주는 도구이다. 지난 doik스터디때 몇 번 사용해 본적이 있었는데, 당시에는 이걸 언제 쓰는걸까.. 하고 생각을 했었는데, 위 사례와 같은 경우에 쓰나싶다. 영상을 보시고 테스트해보셨다는 분의 글을 보고 따라해봤다. 🔗
# install keda
(eunyoung@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# helm repo add kedacore https://kedacore.github.io/charts
"kedacore" has been added to your repositories
(eunyoung@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# helm install keda kedacore/keda --namespace keda --create-namespace
NAME: keda
LAST DEPLOYED: Sun May 28 06:44:23 2023
NAMESPACE: keda
STATUS: deployed
REVISION: 1
TEST SUITE: None
# create scaleobject
# 특정 시간에 어느 정도로 미리 확장을 시켜서 노드 수를 확보함
(eunyoung@myeks2:N/A) [root@myeks2-bastion-EC2 ~]# cat scale.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-over-provioning
spec:
# target
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: inflate
triggers:
- type: cron
metadata:
timezone: Asia/Seoul
start: 03 * * * *
end: 10 * * * *
desiredReplicas: "5"
# 위 시간마다 5개로 확장되도록 설정
# deploy yaml 수정
spec:
...
affinity:
# 사용할 노드(provisioner) 선택
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: team
operator: In
values:
- team1
# 노드마다 파드가 하나씩 뜨도록 pod anti affinity를 사용하여 자신을 넣는다.
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- inflate
topologyKey: "kubernetes.io/hostname"
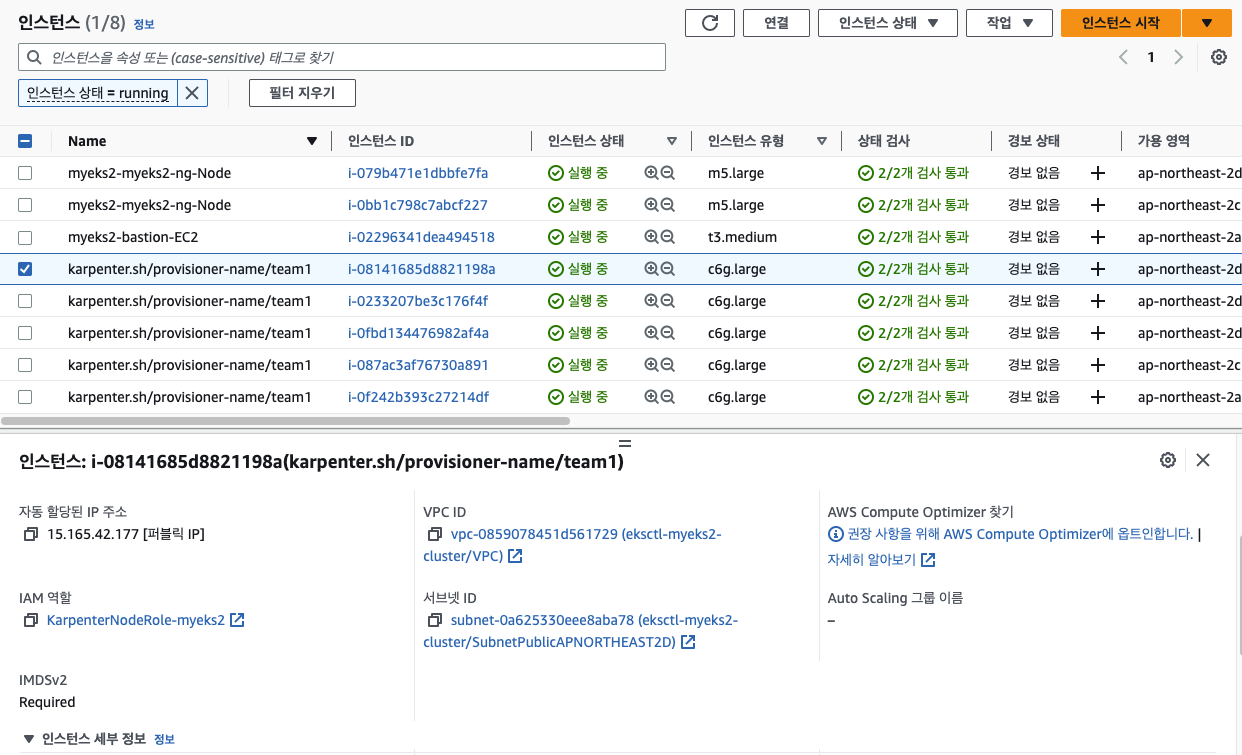 👩🌾 잘 늘어난다.
👩🌾 잘 늘어난다.