KANS3) GKE에서 Calico 체험기
calico
이번 주차에서는 calico cni에 대한 내용이였다. 늘 어떤 주제로 숙제를 할지 고민하는 것이 시작의 반인데, 이번엔 gke에서의 calico cni를 사용해보며 native cluster에서 사용하는 것과 뭐가 다른지 확인해봤다. gke에서는 ‘Enable Calico Kubernetes Network Policy’ 옵션을 선택하면, calico cni를 이용하는 클러스터를 만들 수 있다. 근데 이제 퍼블릭 클라우드에서 동작하는 vpc 환경에서 올라오는 클러스터이다 보니, native k8s 클러스터에서의 calico cni와 좀 다른 점이 있다. 옵션명에서 보는 것과 같이, gke에 있는 enable calico를 설정하게되면 클러스터 내에서 network policy를 설정 할 수 있다는 것이 가장 큰 점이다. (기본 클러스터에서 사용자가 만든network policy는 무시된다.)
calico cni 동작 🔗

설정한 값에 따라 다르겠지만, 일반적으로 native cluster에 calico cni를 구성한 경우로 작성하였다.
kubectl 이나 calicoctl 을 사용하여 생성, 변경하게 되는 경우 etcd가 아니라 calico datastore에 변경사항이 저장된다.
calico cni 설치시, 데몬셋으로 calico-node pod가 생성되는데 내부에는 bird, felix, confd 프로세스가 동작한다.
- bird는 bgp를 통해 서로 간의 대역대를 학습하고 이를 통해 다른 노드의 파드들과 통신 할 수 있다.
- felix는 bird를 통해 학습한 대역을 노드 라우팅 테이블에 업데이트 하여 iptables 규칙을 설정, 관리 한다.
- confd는 calico datastore에서 변경이 일어나면, conf가 받아와 bird에게 전달한다.
이렇게 구성된 calico-node만을 사용할 수도 있지만, 성능 효율을 위해 typha를 두어 사용 할 수도 있다. 🔗 typha는 felix, confd 등을 대신하여 datastore와 연결되어 중간 역할을 하게된다. 하나의 typha에서 여러 felix 를 지원할 수 있기 때문에, datastore의 부하가 줄어든다. felix의 경우에도 datastore에서 felix와는 관련없는 업데이트 값에 대해서는 필터링되기 때문에 felix가 사용하게되는 cpu 사용량도 줄게 된다.
마지막으로, calico는 자체 ipam(ip address management) 플러그인을 가지고 있다. 노드 대역과 연관되지 않은 ip대역을 ip pool로 구성 후, ip pool 리소스를 사용하여 pod 생성시 ip주소가 할당되는 방식이다. 🔗
google cloud와 caclico 🔗
calico 문서에서 google cloud 를 살펴보면, 아래와 같이 나온다. host local ipam을 사용하여, alias ip range가 붙어 할당된다.

google cloud 네트워크는 가상화된 네트워크 환경으로 GCP의 VPC 특성에 따라 managed service가 제공된다. 그래서 위와 같이 ipam이나 routing 모두 vpc를 기반으로 동작한다. overlay 또한 사용하지 않는다. 이는 gke가 flat mode로 동작하기에, overlay를 사용하지 않는 것으로 보인다. flat mode는 클러스터 내의 pod, svc ip 모두 vpc내에서는 동일한 레벨에서 동작하는 것으로 eks도 gke와 동일하게 flat mode로 동작한다.
gke
gke는 vpc-native 모드의 퍼블릭 클러스터로 아래 대역대를 지정하여 생성하였다.
- node ip range: 10.0.0.0/24
- pod id range: 192.168.0.0/21
- svc ip range: 192.168.8.0/24
클러스터 및 노드 확인
생성 후 클러스터를 확인해봤다.
# calico typha 가 돌고 있는 것을 확인
❯ k cluster-info
Kubernetes control plane is running at https://34.47.90.255
calico-typha is running at https://34.47.90.255/api/v1/namespaces/kube-system/services/calico-typha:calico-typha/proxy
GLBCDefaultBackend is running at https://34.47.90.255/api/v1/namespaces/kube-system/services/default-http-backend:http/proxy
KubeDNS is running at https://34.47.90.255/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
Metrics-server is running at https://34.47.90.255/api/v1/namespaces/kube-system/services/https:metrics-server:/proxy
calico 관련 리소스들을 보기 위해 calicoctl를 설치 🔗
❯ curl -L https://github.com/projectcalico/calico/releases/download/v3.28.1/calicoctl-darwin-amd64 -o calicoctl
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 64.7M 100 64.7M 0 0 8186k 0 0:00:08 0:00:08 --:--:-- 9749k
❯ sudo chmod +x calicoctl
❯ sudo mv calicoctl /usr/local/bin/
❯ calicoctl version
Client Version: v3.28.1
Git commit: 601856343
Cluster Version: v3.26.3-gke.16
Cluster Type: kdd,typha
# calico가 관리하는 workload enpoint를 확인해보면, calico 관련한 것은 calico node와 calico typha가 있음을 확인
❯ calicoctl get wep -A --allow-version-mismatch
NAMESPACE WORKLOAD NODE NETWORKS INTERFACE
gke-managed-cim kube-state-metrics-0 gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.6/32 cali6a364803b2a
gmp-system collector-4895p gke-nyoung-cluster-nyoung-pool-da17714f-205w 192.168.1.2/32 cali2aa1a9aa779
gmp-system collector-sjslg gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.15/32 calia849c3b8fcb
gmp-system gmp-operator-bfffcf5f7-jphnr gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.4/32 calieffca38c9b5
kube-system calico-node-vertical-autoscaler-97b44798d-vtkjx gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.14/32 cali3b13b7abbec
kube-system calico-typha-horizontal-autoscaler-6f6645b6b-2rhnf gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.2/32 cali8af86d09e4b
kube-system calico-typha-vertical-autoscaler-85b9f87f59-hgfv2 gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.7/32 cali448b42ba98d
kube-system event-exporter-gke-78fb679b7b-fp6mb gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.10/32 cali69cda6920c1
kube-system konnectivity-agent-5b65f6bc89-75cjt gke-nyoung-cluster-nyoung-pool-da17714f-205w 192.168.1.3/32 calid8485bdd706
kube-system konnectivity-agent-5b65f6bc89-v497h gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.13/32 cali0aece747a34
kube-system konnectivity-agent-autoscaler-897d4f648-lrwhv gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.9/32 calid98f6d36a40
kube-system kube-dns-5879b6df8f-7mpgp gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.3/32 cali6430a18f7ba
kube-system kube-dns-5879b6df8f-snchs gke-nyoung-cluster-nyoung-pool-da17714f-205w 192.168.1.4/32 calic906454c831
kube-system kube-dns-autoscaler-6f896b6968-ggdnd gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.11/32 cali11af904b43f
kube-system l7-default-backend-6697bb6dfd-8mhzl gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.5/32 cali33a8b6c365c
kube-system metrics-server-v1.30.3-54cbdc6d8-kkthh gke-nyoung-cluster-nyoung-pool-da17714f-m732 192.168.0.12/32 cali50d12e2278a
❯ calicoctl ipam show --allow-version-mismatch
+----------+------+-----------+------------+----------+
| GROUPING | CIDR | IPS TOTAL | IPS IN USE | IPS FREE |
+----------+------+-----------+------------+----------+
+----------+------+-----------+------------+----------+
❯ calicoctl get ippool -owide --allow-version-mismatch
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED DISABLEBGPEXPORT SELECTOR
20:25: 20:25:46
❯ calicoctl ipam show --show-configuration --allow-version-mismatch
+--------------------+-------+
| PROPERTY | VALUE |
+--------------------+-------+
| StrictAffinity | false |
| AutoAllocateBlocks | true |
| MaxBlocksPerHost | 0 |
+--------------------+-------+
# 이 밖에도 bgp나 felix관련한 리소스 ippool 검색시 아무것도 나오지 않는다.
# calico ipam을 사용하지 않아, calicoctl명령어를 통해 확인 할 수 있는게 없다.
# calico ipam을 사용한다면, ipam show를 해서 나온 대역대를 사용했겠지만,
# host ipam을 사용하기때문에 Kubectl로 가져온 대역을 사용하게된다.
❯ kubectl get nodes -o jsonpath='{.items[*].spec.podCIDR}' ;echo
192.168.1.0/24 192.168.0.0/24
하나의 노드에 접근하여 내부를 확인해봤다. 일반적으로 사용하는 calico ipip mode의 경우 overlay network이기 때문에 tunnel 인터페이스가 존재하지만, gke에서는 alias ip를 사용한 vpc native cluster라 tunnel 인터페이스가 없다. 🔗
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ ip -c add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc mq state UP group default qlen 1000
link/ether 42:01:0a:00:00:18 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.24/32 metric 1024 scope global dynamic eth0
valid_lft 2551sec preferred_lft 2551sec
inet6 fe80::4001:aff:fe00:18/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:1e:46:c3:4c brd ff:ff:ff:ff:ff:ff
inet 169.254.123.1/24 brd 169.254.123.255 scope global docker0
valid_lft forever preferred_lft forever
6: cali2aa1a9aa779@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-5601c1dc-4e20-669f-5707-d3f742d1b173
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
7: calid8485bdd706@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-b2c6b41d-ccfa-5161-ac6b-bc0c63ebb6a9
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
8: calic906454c831@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-1eb943c1-4bed-7c5a-b98e-497e3010bda0
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
# host-local ipam을 사용하게 되면서 서로의 대역을 bgp로 광고하는 bird 필요없어서.. bird로 광고받은 대역이 없다.(bird가 없다..)
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ ip -c route
default via 10.0.0.1 dev eth0 proto dhcp src 10.0.0.24 metric 1024
10.0.0.1 dev eth0 proto dhcp scope link src 10.0.0.24 metric 1024
169.254.123.0/24 dev docker0 proto kernel scope link src 169.254.123.1 linkdown
169.254.169.254 via 10.0.0.1 dev eth0 proto dhcp src 10.0.0.24 metric 1024
192.168.1.2 dev cali2aa1a9aa779 scope link
192.168.1.3 dev calid8485bdd706 scope link
192.168.1.4 dev calic906454c831 scope link
# 서비스를 올리기 전 기본으로 생성되어있는 iptables rule 갯수 확인
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ sudo iptables -t nat -L | wc -l
178
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ sudo iptables -t filter -L | wc -l
264
pod1 > pod2
생성
❯ cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
nodeName: node1
containers:
- name: pod1
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
spec:
nodeName: node2
containers:
- name: pod2
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
23:31:17
❯ k apply -f pod.yaml
pod/pod1 created
pod/pod2 created 23:31:33
❯ k get po -owide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod1 1/1 Running 0 2m53s 192.168.1.9 gke-nyoung-cluster-nyoung-pool-da17714f-205w <none> <none>
pod2 1/1 Running 0 2m53s 192.168.1.10 gke-nyoung-cluster-nyoung-pool-da17714f-205w <none> <none>
# pod1
❯ k exec -it pod1 -- /bin/sh
~ # ip -c add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether 8e:b1:e4:85:3c:63 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.1.9/32 scope global eth0
valid_lft forever preferred_lft forever
~ # ip -c route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
# 처음에는 arp table에 아무것도 없다.
~ # arp -n
# pod2
❯ k exec -it pod2 -- /bin/sh
~ # ip -c a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if16: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether 4a:24:e5:6d:cf:84 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.1.10/32 scope global eth0
valid_lft forever preferred_lft forever
~ # ip -c route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
~ # arp -n
ping
# pod1: pod1 > pod2
~ # ping -c 3 192.168.1.10
PING 192.168.1.10 (192.168.1.10) 56(84) bytes of data.
64 bytes from 192.168.1.10: icmp_seq=1 ttl=63 time=0.173 ms
64 bytes from 192.168.1.10: icmp_seq=2 ttl=63 time=0.091 ms
64 bytes from 192.168.1.10: icmp_seq=3 ttl=63 time=0.095 ms
--- 192.168.1.10 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2036ms
rtt min/avg/max/mdev = 0.091/0.119/0.173/0.037 ms
# pod가 있는 node에서 pod1의 interface에 대해 tcpdump를 떠보면,
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ ip -c add
...
16: calibd2348b4f67@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-567e113e-68c2-da7c-8c3b-ffb07fc165ed
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
root@gke-nyoung-cluster-nyoung-pool-da17714f-205w:~# tcpdump -i calibd2348b4f67
# 먼저 노드에서 pod2(192.168.1.10)의 mac주소는 arp 테이블에서 확인이 되기 때문에, pod2의 mac주소가 반환됨
15:56:06.009527 ARP, Request who-has 192.168.1.10 tell gke-nyoung-cluster-nyoung-pool-da17714f-205w.asia-northeast3-a.c.project_id.internal, length 28
15:56:06.009542 ARP, Reply 192.168.1.10 is-at 4a:24:e5:6d:cf:84 (oui Unknown), length 28
# pod1(192.168.1.9) > pod2(192.168.1.10) 으로 icmp request를 날림
15:56:06.009545 IP 192.168.1.9 > 192.168.1.10: ICMP echo request, id 16, seq 1, length 64
# 요천된 icmp를 처리하기 위해 pod2(192.168.1.10)는 기본 gw로 지정된 169.254.1.1의 mac주소를 요청한다.
# 이에 대해 proxy arp가 가상의 mac주소를 반환하게 된다.
15:56:06.009564 ARP, Request who-has 169.254.1.1 tell 192.168.1.10, length 28
15:56:06.009567 ARP, Reply 169.254.1.1 is-at ee:ee:ee:ee:ee:ee (oui Unknown), length 28
15:56:06.009571 IP 192.168.1.10 > 192.168.1.9: ICMP echo reply, id 16, seq 1, length 64
...
proxy arp
여기서 말하는 gateway, 169.254.1.1은 실제 호스트의 gateway가 아니라 calico에서 각 pod와 연결된 인터페이스에 proxy_arp 플래그를 설정해둔 것이다. 🔗 실제로 ip주소를 인터페이스에 할당하지 않았더라도, 169.254.1.1에 대해 arp요청이 들어오면 이에 대해 pod 인터페이스가 응답을 해준다.
# 노드에서 pod와 연결된 interface의 proxy_arp를 확인
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ ip -c add
...
17: calice0906292e2@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-84827d09-c36f-72b6-778a-5d7ff48349a2
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
18: calibd2348b4f67@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-8827ba99-9d87-4148-37b5-63e9883993a4
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
# node의 interface eht0는 proxy arp가 설정되지 않음
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ cat /proc/sys/net/ipv4/conf/eth0/proxy_arp
0
# pod와 연결된 interface들은 모두 proxy arp가 설정되어있다. 해당 값이 0으로 비활성화 되면, 통신을 하지 못하게 된다.
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ cat /proc/sys/net/ipv4/conf/calice0906292e2/proxy_arp
1
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ cat /proc/sys/net/ipv4/conf/calice0906292e2/proxy_arp
1
# node에서 iptables rule 갯수를 다시 확인해보면, filter table이 pod당 40개 가량 늘었다.
# overlay가 아니여서 nat table의 수는 변경 없다.
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ sudo iptables -t nat -L | wc -l
178
eunyoung@gke-nyoung-cluster-nyoung-pool-da17714f-205w ~ $ sudo iptables -t filter -L | wc -l
344
전후과정에 대해 더 보려고, 새로 띄워서 pod1에서 tcpdump를 떴다. pod1(192.168.1.11) > pod2(192.168.1.12)
# pod1에서 출발 할 때도 기본 gw로 지정된 169.254.1.1의 mac주소를 요청하여 받는다.
(pod1) 16:08:16.947359 ARP, Request who-has 169.254.1.1 tell pod1, length 28
(pod1) 16:08:16.947387 ARP, Reply 169.254.1.1 is-at ee:ee:ee:ee:ee:ee (oui Unknown), length 28
# pod1에서 pod2(192.168.1.12)로 icmp 요청
(pod1) 16:08:16.947392 IP pod1 > 192.168.1.12: ICMP echo request, id 27, seq 1, length 64
# 노드에서 pod2로 arp 요청 후 전달하면 icmp 요청이 들어온다.
(pod2) 16:08:16.947458 ARP, Request who-has pod2 tell gke-nyoung-cluster-nyoung-pool-da17714f-205w.asia-northeast3-a.c.project_id.internal, length 28
(pod2) 16:08:16.947469 ARP, Reply pod2 is-at e6:0e:ad:ba:c4:77 (oui Unknown), length 28
(pod2) 16:08:16.947472 IP 192.168.1.11 > pod2: ICMP echo request, id 27, seq 1, length 64
# pod2에 기본 gw인 169.254.1.1에 arp 요청 후 icmp 응답이 간다.
(pod2) 16:08:16.947484 ARP, Request who-has 169.254.1.1 tell pod2, length 28
(pod2) 16:08:16.947488 ARP, Reply 169.254.1.1 is-at ee:ee:ee:ee:ee:ee (oui Unknown), length 28
(pod2) 16:08:16.947490 IP pod2 > 192.168.1.11: ICMP echo reply, id 27, seq 1, length 64
(pod1) 16:08:16.947501 IP 192.168.1.12 > pod1: ICMP echo reply, id 27, seq 1, length 64
...
# 내 생각으로는 16:08:16.947490 과 16:08:16.947501 사이에 pod1을 묻는 arp가 한번 더 있을 것으로 생각되었는데.. 아무것도 없었다.
# 왜인지.. icmp통신을 모두 마친 뒤, 16:08:22에 pod1에 아래와 같이 arp통신이 일어났다.
(pod1) 16:08:22.189952 ARP, Request who-has pod1 tell gke-nyoung-cluster-nyoung-pool-da17714f-205w.asia-northeast3-a.c.project_id.internal, length 28
(pod1) 16:08:22.190075 ARP, Reply pod1 is-at 32:ae:50:1c:7c:42 (oui Unknown), length 28
# 위와 같이 통신하고나면, 각 파드에는 아래와 같이 arp 테이블이 생성된다.
~ # arp -n
? (169.254.1.1) at ee:ee:ee:ee:ee:ee [ether] on eth0
? (10.0.0.23) at ee:ee:ee:ee:ee:ee [ether] on eth0
network policy
calico 문서에서 gke 부분을 보면, network policy api 이야기 밖에 없다..🐟 🔗
# 아래 yaml들로 all deny와 app:test2에서 app:test1로 80포트 접근 허용을 만들었다.
❯ cat denyall.yaml
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: denyall
spec:
podSelector:
matchLabels: {}
policyTypes:
- Ingress
- Egress
❯ cat allow80.yaml
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-ingress
spec:
podSelector:
matchLabels:
app: test1
egress:
- from:
- podSelector:
matchLabels:
app: test2
ports:
- port: 80
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-egress
spec:
podSelector:
matchLabels:
app: test2
egress:
- to:
- podSelector:
matchLabels:
app: test1
ports:
- port: 80
❯ k get networkpolicy
NAME POD-SELECTOR AGE
allow-egress app=test2 8m10s
allow-ingress app=test1 11m
denyall <none> 13m
# 각 라벨을 달아 nginx pod를 띄웠다.
❯ kubectl run test-web1 --labels app=test1 --image=nginx --port 80
❯ kubectl run test-web2 --labels app=test2 --image=nginx --port 80
❯ k get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-web1 1/1 Running 0 17m 192.168.1.13 gke-nyoung-cluster-nyoung-pool-da17714f-205w <none> <none>
test-web2 1/1 Running 0 17m 192.168.1.14 gke-nyoung-cluster-nyoung-pool-da17714f-205w <none> <none>
deny policy만 있을때는 양쪽 모두 접근이 불가했지만, allow policy 추가 후 test-web2에서는 test-web1에 접근이 가능해졌다.
03:30:02
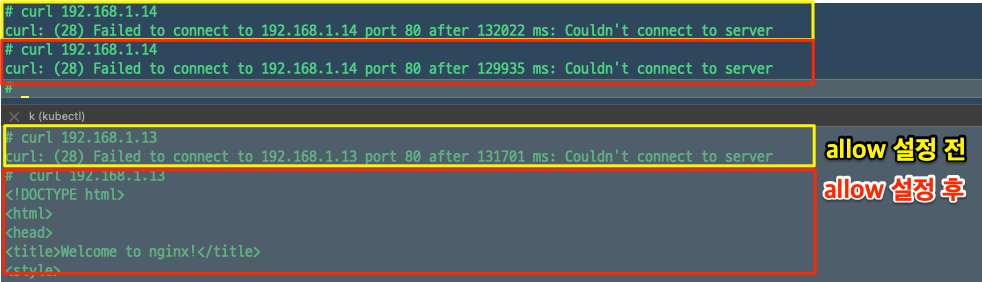
network policy를 생성한다고 gcp 콘솔 상에 firewall이나 policy가 따로 생성되지는 않는다.

이후로는 안될 것 같았지만..(진짜 안됨) 첫번째 클러스터에서 이것저것 뒤져보다 궁금증이 생겨 테스트 해본 것들이다.
❯ k describe DaemonSet/calico-node -n kube-system
...
Init Containers:
install-cni-template:
...
Environment:
ENABLE_CALICO_NETWORK_POLICY: true
CNI_SPEC_NAME: 10-calico.conflist.template
CNI_SPEC_TEMPLATE: {
"name": "gke-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "calico",
"mtu": 1460,
"log_level": "info",
"log_file_path": "/var/log/calico/cni/cni.log",
"datastore_type": "kubernetes",
"nodename": "__KUBERNETES_NODE_NAME__",
"nodename_file_optional": true,
"ipam": {
"type": "host-local",
...
...
Containers:
calico-node:
...
Environment:
CALICO_CNI_SERVICE_ACCOUNT: calico-cni-sa
CALICO_MANAGE_CNI: true
CALICO_DISABLE_FILE_LOGGING: true
CALICO_NETWORKING_BACKEND: none
DATASTORE_TYPE: kubernetes
FELIX_DEFAULTENDPOINTTOHOSTACTION: ACCEPT
FELIX_HEALTHENABLED: true
FELIX_IGNORELOOSERPF: false
FELIX_IPTABLESMANGLEALLOWACTION: RETURN
FELIX_IPV6SUPPORT: false
FELIX_LOGFILEPATH: none
FELIX_LOGSEVERITYSYS: none
FELIX_LOGSEVERITYSCREEN: info
FELIX_PROMETHEUSMETRICSENABLED: true
FELIX_REPORTINGINTERVALSECS: 0
FELIX_TYPHAK8SSERVICENAME: calico-typha
FELIX_ROUTETABLERANGE: 10-250
USE_POD_CIDR: true
IP: autodetect
IP_AUTODETECTION_METHOD: kubernetes-internal-ip
NO_DEFAULT_POOLS: true
NODENAME: (v1:spec.nodeName)
WAIT_FOR_DATASTORE: true
...
ipam을 추가했다. 🔗
# 환경변수 보면, NO_DEFAULT_POOLS은 이미 true로 되어있어서, 다른 작업 없이 아래 ipam yaml을 적용했다.
❯ calicoctl create --allow-version-mismatch -f -<<EOF
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: pool-zone-1
spec:
cidr: 192.168.50.0/24
vxlanMode: Always
natOutgoing: true
EOF
Successfully created 1 'IPPool' resource(s)
❯ calicoctl ipam show --allow-version-mismatch
+----------+-----------------+-----------+------------+------------+
| GROUPING | CIDR | IPS TOTAL | IPS IN USE | IPS FREE |
+----------+-----------------+-----------+------------+------------+
| IP Pool | 192.168.50.0/24 | 256 | 0 (0%) | 256 (100%) |
+----------+-----------------+-----------+------------+------------+
❯ calicoctl get ippool -owide --allow-version-mismatch
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED DISABLEBGPEXPORT SELECTOR
pool-zone-1 192.168.50.0/24 true Never Always false false all()
# 노드에 들어가서 config 파일을 변경해줬다.
eunyoung@gke-nyoung-cluster-nyoung-pool-0f26b766-1wp8 ~ $ sudo vi /etc/cni/net.d/10-calico.conflist
...
"ipam": {
"type": "calico-ipam",
...
# 노드에 들어가서 calico ipam을 쓰도록 수동 변경을 해줬기 때문에, 노드 재생성시 기본으로 calico ipam을 잡지 못한다.
# 그래서 혹시나 싶어 configmap에서도 변경해봤지만, 역시나.. configmap은 변경되지 않는다.
❯ k edit cm netd-config -n kube-system
configmap/netd-config edited
❯ k describe cm netd-config -n kube-system
...
"plugins": [
{...
"ipam": {
"type": "host-local",
...
# vxlan interface가 생성되지 않는다..
eunyoung@gke-nyoung-cluster-nyoung-pool-0f26b766-1wp8 ~ $ ip -c add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc mq state UP group default qlen 1000
link/ether 42:01:0a:00:00:14 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.20/32 metric 1024 scope global dynamic eth0
valid_lft 2969sec preferred_lft 2969sec
inet6 fe80::4001:aff:fe00:14/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:65:54:66:9a brd ff:ff:ff:ff:ff:ff
inet 169.254.123.1/24 brd 169.254.123.255 scope global docker0
valid_lft forever preferred_lft forever
4: calie989573d8f9@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-f2eb30bb-db1a-8361-7379-cff2fb15627c
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
5: calidaa2afa5d01@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-9414d9fa-0232-79d6-f162-3a385c3fd3a4
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
9: cali0bc39c653a0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-148ccca2-dbdc-e82e-d867-b14cbda0a6e4
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
eunyoung@gke-nyoung-cluster-nyoung-pool-0f26b766-1wp8 ~ $ ip -c route
default via 10.0.0.1 dev eth0 proto dhcp src 10.0.0.20 metric 1024
10.0.0.1 dev eth0 proto dhcp scope link src 10.0.0.20 metric 1024
169.254.123.0/24 dev docker0 proto kernel scope link src 169.254.123.1 linkdown
169.254.169.254 via 10.0.0.1 dev eth0 proto dhcp src 10.0.0.20 metric 1024
192.168.1.2 dev calie989573d8f9 scope link
192.168.1.3 dev calidaa2afa5d01 scope link
192.168.1.5 dev cali0bc39c653a0 scope link
pod를 생성해서 확인
# pod1은 설정 전에 생성한 pod
# pod2는 ipam 추가 후 생성한 pod
❯ k get po -owide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod1 1/1 Running 0 3m28s 192.168.1.6 gke-nyoung-cluster-nyoung-pool-0f26b766-1wp8 <none> <none>
pod2 1/1 Running 0 36s 192.168.50.0 gke-nyoung-cluster-nyoung-pool-0f26b766-1wp8 <none> <none>
❯ k exec -it pod2 -- /bin/sh
~ # ip -c route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
~ # ip -c add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1460 qdisc noqueue state UP group default qlen 1000
link/ether 02:19:85:88:d6:d8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.50.0/32 scope global eth0
valid_lft forever preferred_lft forever
# pod1 과 pod2 간의 통신이 잘된다.
~ # ping -c 3 192.168.1.6
PING 192.168.1.6 (192.168.1.6) 56(84) bytes of data.
64 bytes from 192.168.1.6: icmp_seq=1 ttl=63 time=0.114 ms
64 bytes from 192.168.1.6: icmp_seq=2 ttl=63 time=0.089 ms
64 bytes from 192.168.1.6: icmp_seq=3 ttl=63 time=0.081 ms
--- 192.168.1.6 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2058ms
rtt min/avg/max/mdev = 0.081/0.094/0.114/0.014 ms
❯ k exec -it pod1 -- /bin/sh
~ # ping -c 3 192.168.50.0
PING 192.168.50.0 (192.168.50.0) 56(84) bytes of data.
64 bytes from 192.168.50.0: icmp_seq=1 ttl=63 time=0.104 ms
64 bytes from 192.168.50.0: icmp_seq=2 ttl=63 time=0.075 ms
64 bytes from 192.168.50.0: icmp_seq=3 ttl=63 time=0.083 ms
--- 192.168.50.0 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2068ms
rtt min/avg/max/mdev = 0.075/0.087/0.104/0.012 ms
node 단에서 tcpdump떠봤는데, 그냥 node ip만 나왔다. pod 단에서도 떠볼걸.. 이때는 아무생각없이 해서 노드에서만 인터페이스
# ipip mode로 변경
❯ calicoctl get ippool pool-zone-1 -o wide --allow-version-mismatch
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED DISABLEBGPEXPORT SELECTOR
pool-zone-1 192.168.50.0/24 true Never Always false false all()
❯ calicoctl get ippool default-ipv4-ippool -o yaml > test.yaml
❯ cat test.yaml
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
creationTimestamp: "2024-09-22T14:31:46Z"
name: pool-zone-1
resourceVersion: "838821"
uid: b9142f28-928f-4e4c-b97d-10ea3ec5ab85
spec:
allowedUses:
- Workload
- Tunnel
blockSize: 26
cidr: 192.168.50.0/24
ipipMode: CrossSubnet
natOutgoing: true
nodeSelector: all()
vxlanMode: Never
❯ calicoctl apply -f test.yaml
❯ calicoctl get ippool pool-zone-1 -o wide --allow-version-mismatch
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED DISABLEBGPEXPORT SELECTOR
pool-zone-1 192.168.50.0/24 true CrossSubnet Never false false all()
eunyoung@gke-nyoung-cluster-nyoung-pool-0f26b766-1wp8 ~ $ ip -c add
...
16: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 192.168.1.1/32 scope global tunl0
valid_lft forever preferred_lft forever
tunnel이 생기긴하는데, 이를 통해서 통신하는 것은 아닌듯하다.. tcpdump를 떠봤는데, dst나 src을 잡거나 tunnel 인터페이스 생겼길래 이걸로도 떠봤는데, node ip간에 icmp 날리는 것만 나왔다. 어디하나 ipip라든가, vxlan을 확인하지 못했다.
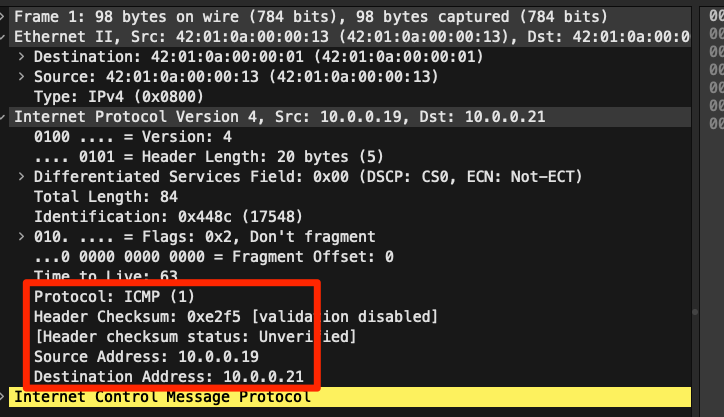
신기한게 192.168.50.x으로 생겼던 pod들과 연결된 interface는 node에서 확인하지 못했다. 그럼에도 16번이 나온거보면.. 15번까지의 친구들이 어딘가 있었던거 같긴한데.. 알 수가 없다. 안되는거를 그냥 해본거라.. 첫번째 클러스터는 이렇게 지우고 (위에서 테스트 한)두번째 클러스터를 다시 만들었다.
참고